Starkes Forschungsnetzwerk mit Zukunftspersprektive
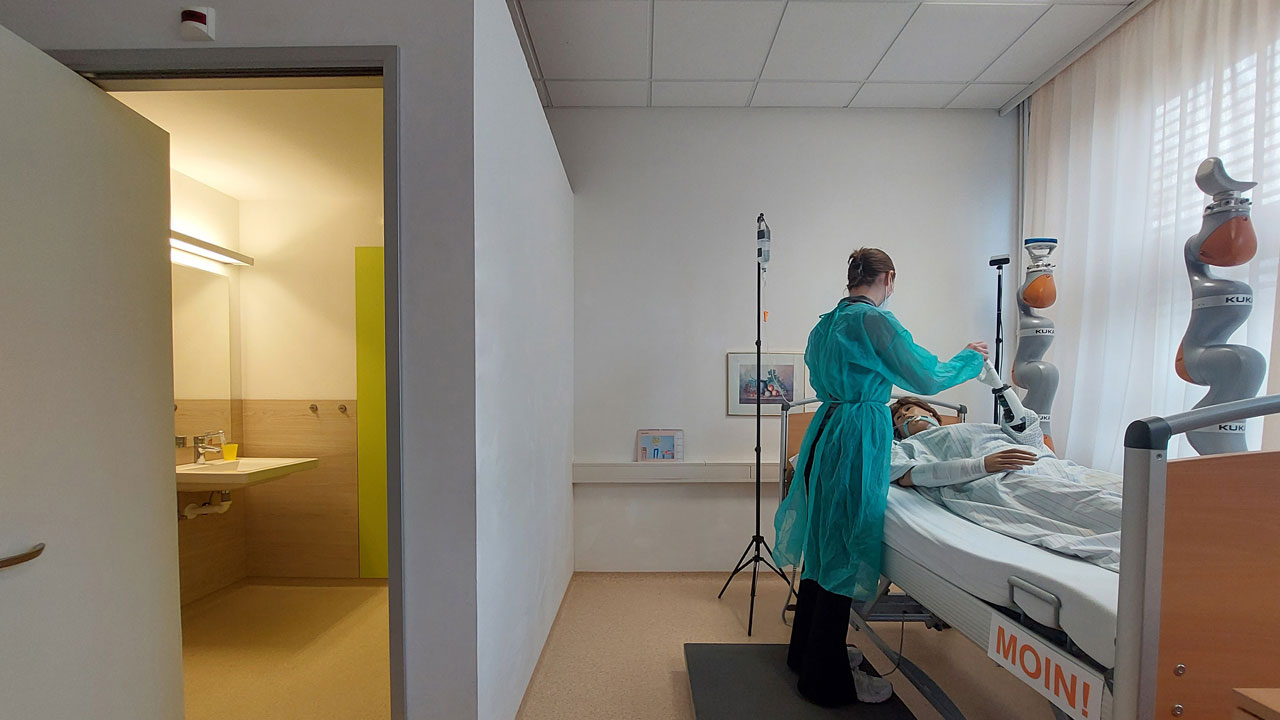
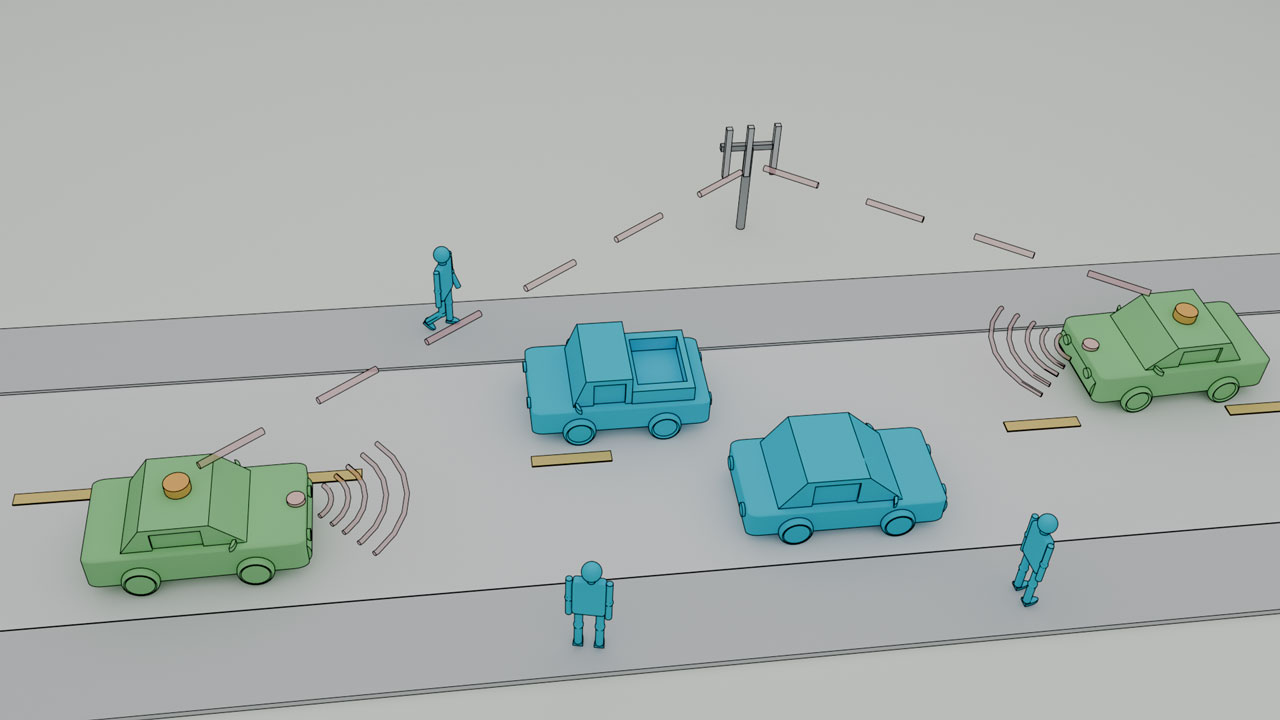
Das Zentrum für digitale Innovationen Niedersachsen (ZDIN) vernetzt die Spitzenreiter der niedersächsischen Digitalisierungsforschung, um die digitale Transformation des Landes aktiv zu gestalten. Das umfangreiche ZDIN-Netzwerk aus Wissenschaft und Wirtschaft spannt sich über ganz Niedersachsen. Gemeinsam verzeichnen die Zukunftslabore (Agrar, Circular Economy, Energie, Gesellschaft & Arbeit, Gesundheit, Mobilität, Produktion und Wasser) und die Koordinierungsstelle beeindruckende Projekterfolge, die sie in den nächsten Jahren fortführen werden.
Die Wissenschaftler*innen, Hochschulen und Forschungseinrichtungen sowie Praxispartnern des ZDIN entwickeln im Sinne einer Denkfabrik zukunftsweisende Ideen und Lösungen. Die anwendungsorientierten Forschungstätigkeiten des Landes werden gebündelt und koordiniert mit einem gemeinsamen Ziel: den Digitalisierungsstandort Niedersachsen zu stärken.
In themenspezifischen Plattformen – den Zukunftslaboren Digitalisierung – kooperieren Wissenschaftler*innen aus Hochschulforschung und außeruniversitärer Forschung mit Partnern aus der Wirtschaft. Gemeinsam bearbeiten sie branchenspezifische Fragestellungen der Digitalisierung und transformieren die Ergebnisse zu anwendungsfähigen Lösungen. Inhaltlich sind die Zukunftslabore an den Bereichen ausgerichtet, die für Niedersachsen gesellschaftlich, wirtschaftlich und politisch besonders wichtig sind: Agrar, Circular Economy, Energie, Gesellschaft & Arbeit, Gesundheit, Mobilität, Produktion und Wasser. Kollaborative Projekte und produktive Partnerschaften sind für die Zukunftslabore von großer Bedeutung; sie geben neue Impulse für die Forschung und stellen den Bezug zur Wirtschaft her.